[1]:
import eland as ed
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Fix console size for consistent test results
from eland.conftest import *
Online Retail Analysis#
Getting Started#
To get started, let’s create an eland.DataFrame by reading a csv file. This creates and populates the online-retail index in the local Elasticsearch cluster.
[2]:
df = ed.csv_to_eland("data/online-retail.csv.gz",
es_client='http://localhost:9200',
es_dest_index='online-retail',
es_if_exists='replace',
es_dropna=True,
es_refresh=True,
compression='gzip',
index_col=0)
Here we see that the "_id" field was used to index our data frame.
[3]:
df.index.es_index_field
[3]:
'_id'
Next, we can check which field from elasticsearch are available to our eland data frame. columns is available as a parameter when instantiating the data frame which allows one to choose only a subset of fields from your index to be included in the data frame. Since we didn’t set this parameter, we have access to all fields.
[4]:
df.columns
[4]:
Index(['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode',
'UnitPrice'],
dtype='object')
Now, let’s see the data types of our fields. Running df.dtypes, we can see that elasticsearch field types are mapped to pandas field types.
[5]:
df.dtypes
[5]:
Country object
CustomerID float64
Description object
InvoiceDate object
InvoiceNo object
Quantity int64
StockCode object
UnitPrice float64
dtype: object
We also offer a .es_info() data frame method that shows all info about the underlying index. It also contains information about operations being passed from data frame methods to elasticsearch. More on this later.
[6]:
print(df.es_info())
es_index_pattern: online-retail
Index:
es_index_field: _id
is_source_field: False
Mappings:
capabilities:
es_field_name is_source es_dtype es_date_format pd_dtype is_searchable is_aggregatable is_scripted aggregatable_es_field_name
Country Country True keyword None object True True False Country
CustomerID CustomerID True double None float64 True True False CustomerID
Description Description True keyword None object True True False Description
InvoiceDate InvoiceDate True keyword None object True True False InvoiceDate
InvoiceNo InvoiceNo True keyword None object True True False InvoiceNo
Quantity Quantity True long None int64 True True False Quantity
StockCode StockCode True keyword None object True True False StockCode
UnitPrice UnitPrice True double None float64 True True False UnitPrice
Operations:
tasks: []
size: None
sort_params: None
_source: ['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode', 'UnitPrice']
body: {}
post_processing: []
Selecting and Indexing Data#
Now that we understand how to create a data frame and get access to it’s underlying attributes, let’s see how we can select subsets of our data.
head and tail#
much like pandas, eland data frames offer .head(n) and .tail(n) methods that return the first and last n rows, respectively.
[7]:
df.head(2)
[7]:
| Country | CustomerID | ... | StockCode | UnitPrice | |
|---|---|---|---|---|---|
| 0 | United Kingdom | 17850.0 | ... | 85123A | 2.55 |
| 1 | United Kingdom | 17850.0 | ... | 71053 | 3.39 |
2 rows × 8 columns
[8]:
print(df.tail(2).head(2).tail(2).es_info())
es_index_pattern: online-retail
Index:
es_index_field: _id
is_source_field: False
Mappings:
capabilities:
es_field_name is_source es_dtype es_date_format pd_dtype is_searchable is_aggregatable is_scripted aggregatable_es_field_name
Country Country True keyword None object True True False Country
CustomerID CustomerID True double None float64 True True False CustomerID
Description Description True keyword None object True True False Description
InvoiceDate InvoiceDate True keyword None object True True False InvoiceDate
InvoiceNo InvoiceNo True keyword None object True True False InvoiceNo
Quantity Quantity True long None int64 True True False Quantity
StockCode StockCode True keyword None object True True False StockCode
UnitPrice UnitPrice True double None float64 True True False UnitPrice
Operations:
tasks: [('tail': ('sort_field': '_doc', 'count': 2)), ('head': ('sort_field': '_doc', 'count': 2)), ('tail': ('sort_field': '_doc', 'count': 2))]
size: 2
sort_params: {'_doc': 'desc'}
_source: ['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode', 'UnitPrice']
body: {}
post_processing: [('sort_index'), ('head': ('count': 2)), ('tail': ('count': 2))]
[9]:
df.tail(2)
[9]:
| Country | CustomerID | ... | StockCode | UnitPrice | |
|---|---|---|---|---|---|
| 12498 | United Kingdom | 16710.0 | ... | 20975 | 0.65 |
| 12499 | United Kingdom | 16710.0 | ... | 22445 | 2.95 |
2 rows × 8 columns
Selecting columns#
you can also pass a list of columns to select columns from the data frame in a specified order.
[10]:
df[['Country', 'InvoiceDate']].head(5)
[10]:
| Country | InvoiceDate | |
|---|---|---|
| 0 | United Kingdom | 2010-12-01 08:26:00 |
| 1 | United Kingdom | 2010-12-01 08:26:00 |
| 2 | United Kingdom | 2010-12-01 08:26:00 |
| 3 | United Kingdom | 2010-12-01 08:26:00 |
| 4 | United Kingdom | 2010-12-01 08:26:00 |
5 rows × 2 columns
Boolean Indexing#
we also allow you to filter the data frame using boolean indexing. Under the hood, a boolean index maps to a terms query that is then passed to elasticsearch to filter the index.
[11]:
# the construction of a boolean vector maps directly to an elasticsearch query
print(df['Country']=='Germany')
df[(df['Country']=='Germany')].head(5)
{'term': {'Country': 'Germany'}}
[11]:
| Country | CustomerID | ... | StockCode | UnitPrice | |
|---|---|---|---|---|---|
| 1109 | Germany | 12662.0 | ... | 22809 | 2.95 |
| 1110 | Germany | 12662.0 | ... | 84347 | 2.55 |
| 1111 | Germany | 12662.0 | ... | 84945 | 0.85 |
| 1112 | Germany | 12662.0 | ... | 22242 | 1.65 |
| 1113 | Germany | 12662.0 | ... | 22244 | 1.95 |
5 rows × 8 columns
we can also filter the data frame using a list of values.
[12]:
print(df['Country'].isin(['Germany', 'United States']))
df[df['Country'].isin(['Germany', 'United Kingdom'])].head(5)
{'terms': {'Country': ['Germany', 'United States']}}
[12]:
| Country | CustomerID | ... | StockCode | UnitPrice | |
|---|---|---|---|---|---|
| 0 | United Kingdom | 17850.0 | ... | 85123A | 2.55 |
| 1 | United Kingdom | 17850.0 | ... | 71053 | 3.39 |
| 2 | United Kingdom | 17850.0 | ... | 84406B | 2.75 |
| 3 | United Kingdom | 17850.0 | ... | 84029G | 3.39 |
| 4 | United Kingdom | 17850.0 | ... | 84029E | 3.39 |
5 rows × 8 columns
We can also combine boolean vectors to further filter the data frame.
[13]:
df[(df['Country']=='Germany') & (df['Quantity']>90)]
[13]:
| Country | CustomerID | ... | StockCode | UnitPrice |
|---|
0 rows × 8 columns
Using this example, let see how eland translates this boolean filter to an elasticsearch bool query.
[14]:
print(df[(df['Country']=='Germany') & (df['Quantity']>90)].es_info())
es_index_pattern: online-retail
Index:
es_index_field: _id
is_source_field: False
Mappings:
capabilities:
es_field_name is_source es_dtype es_date_format pd_dtype is_searchable is_aggregatable is_scripted aggregatable_es_field_name
Country Country True keyword None object True True False Country
CustomerID CustomerID True double None float64 True True False CustomerID
Description Description True keyword None object True True False Description
InvoiceDate InvoiceDate True keyword None object True True False InvoiceDate
InvoiceNo InvoiceNo True keyword None object True True False InvoiceNo
Quantity Quantity True long None int64 True True False Quantity
StockCode StockCode True keyword None object True True False StockCode
UnitPrice UnitPrice True double None float64 True True False UnitPrice
Operations:
tasks: [('boolean_filter': ('boolean_filter': {'bool': {'must': [{'term': {'Country': 'Germany'}}, {'range': {'Quantity': {'gt': 90}}}]}}))]
size: None
sort_params: None
_source: ['Country', 'CustomerID', 'Description', 'InvoiceDate', 'InvoiceNo', 'Quantity', 'StockCode', 'UnitPrice']
body: {'query': {'bool': {'must': [{'term': {'Country': 'Germany'}}, {'range': {'Quantity': {'gt': 90}}}]}}}
post_processing: []
Aggregation and Descriptive Statistics#
Let’s begin to ask some questions of our data and use eland to get the answers.
How many different countries are there?
[15]:
df['Country'].nunique()
[15]:
16
What is the total sum of products ordered?
[16]:
df['Quantity'].sum()
[16]:
111960
Show me the sum, mean, min, and max of the qunatity and unit_price fields
[17]:
df[['Quantity','UnitPrice']].agg(['sum', 'mean', 'max', 'min'])
[17]:
| Quantity | UnitPrice | |
|---|---|---|
| sum | 111960.000 | 61548.490000 |
| mean | 7.464 | 4.103233 |
| max | 2880.000 | 950.990000 |
| min | -9360.000 | 0.000000 |
Give me descriptive statistics for the entire data frame
[18]:
# NBVAL_IGNORE_OUTPUT
df.describe()
[18]:
| CustomerID | Quantity | UnitPrice | |
|---|---|---|---|
| count | 10729.000000 | 15000.000000 | 15000.000000 |
| mean | 15590.776680 | 7.464000 | 4.103233 |
| std | 1764.189592 | 85.930116 | 20.106214 |
| min | 12347.000000 | -9360.000000 | 0.000000 |
| 25% | 14222.249164 | 1.000000 | 1.250000 |
| 50% | 15663.037856 | 2.000000 | 2.510000 |
| 75% | 17219.040670 | 6.425347 | 4.210000 |
| max | 18239.000000 | 2880.000000 | 950.990000 |
Show me a histogram of numeric columns
[19]:
df[(df['Quantity']>-50) &
(df['Quantity']<50) &
(df['UnitPrice']>0) &
(df['UnitPrice']<100)][['Quantity', 'UnitPrice']].hist(figsize=[12,4], bins=30)
plt.show()
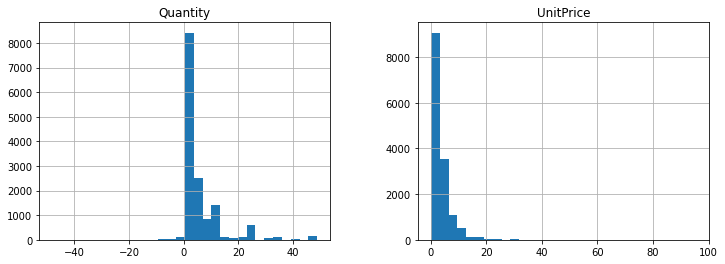
[20]:
df[(df['Quantity']>-50) &
(df['Quantity']<50) &
(df['UnitPrice']>0) &
(df['UnitPrice']<100)][['Quantity', 'UnitPrice']].hist(figsize=[12,4], bins=30, log=True)
plt.show()
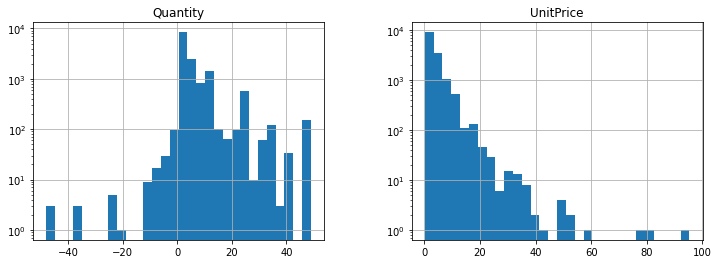
[21]:
df.query('Quantity>50 & UnitPrice<100')
[21]:
| Country | CustomerID | ... | StockCode | UnitPrice | |
|---|---|---|---|---|---|
| 46 | United Kingdom | 13748.0 | ... | 22086 | 2.55 |
| 83 | United Kingdom | 15291.0 | ... | 21733 | 2.55 |
| 96 | United Kingdom | 14688.0 | ... | 21212 | 0.42 |
| 102 | United Kingdom | 14688.0 | ... | 85071B | 0.38 |
| 176 | United Kingdom | 16029.0 | ... | 85099C | 1.65 |
| ... | ... | ... | ... | ... | ... |
| 11924 | United Kingdom | 14708.0 | ... | 84945 | 0.72 |
| 12007 | United Kingdom | 18113.0 | ... | 84946 | 1.06 |
| 12015 | United Kingdom | 17596.0 | ... | 17003 | 0.21 |
| 12058 | United Kingdom | 17596.0 | ... | 84536A | 0.42 |
| 12448 | EIRE | 14911.0 | ... | 84945 | 0.85 |
258 rows × 8 columns
Arithmetic Operations#
Numeric values
[22]:
df['Quantity'].head()
[22]:
0 6
1 6
2 8
3 6
4 6
Name: Quantity, dtype: int64
[23]:
df['UnitPrice'].head()
[23]:
0 2.55
1 3.39
2 2.75
3 3.39
4 3.39
Name: UnitPrice, dtype: float64
[24]:
product = df['Quantity'] * df['UnitPrice']
[25]:
product.head()
[25]:
0 15.30
1 20.34
2 22.00
3 20.34
4 20.34
dtype: float64
String concatenation
[26]:
df['Country'] + df['StockCode']
[26]:
0 United Kingdom85123A
1 United Kingdom71053
2 United Kingdom84406B
3 United Kingdom84029G
4 United Kingdom84029E
...
12495 United Kingdom84692
12496 United Kingdom22075
12497 United Kingdom20979
12498 United Kingdom20975
12499 United Kingdom22445
Length: 15000, dtype: object